The IR Tree - Introduction
The Cone compiler uses a traditional pipeline to transform source programs into object files.
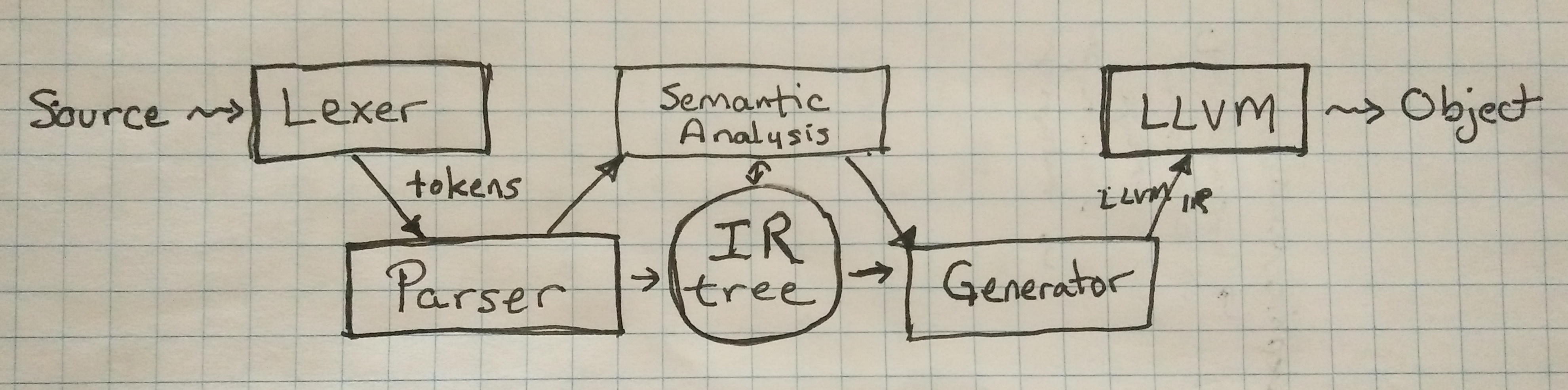
The Intermediate Representation (IR) plays a central role in this design. It is the glue binding together the parser, semantic analysis passes, and the LLVM IR generator.
The literature on effective IR design is relatively sparse as compared to other topics, such as parsing, type inference/theory, and optimization techniques. This is a shame. I have devoted far more time trying to get Cone’s IR “right” than I have on any other aspect of the compiler. And getting it right early has a huge impact on productivity, since each refactor of the IR design has a large multiplying effect on nearly every compiler component.
This series of posts details key design choices I made for Cone’s IR. I hope the described ideas will help other compiler designers. I also look forward to learning about alternative choices made by others.
Design Priorities
I will bring up compiler performance many times, while explaining my choices. A designer’s choices reflect their biases and preferences. Here are mine, ordered by importance:
- Cone’s semantics. If the language requires a feature, the IR must support it.
- Code simplicity. The compiler’s logic should be concise and easy-to-maintain.
- Performance. The compiler should be blazingly fast to facilitate rapid code iteration.
- Memory efficiency. The compiler should be parsimonious in memory consumption.
So far (and it is early), the focus on performance and memory use has yielded promising results. A 45-line Cone program compiles on a small server in 4.5 ms (I suspect most of that time is LLVM and I/O). The ratio of memory consumed per source program size is about 60:1. Scaling up those numbers gives the Cone compiler a lot of room for growth.
These listed priorities have played a huge role in Cone’s design choices. Languages (and designers) with different priorities will understandably and wisely make different ones.
AST vs. High-level IR
Many language compilers distinguish between distinct layers of Intermediate Representation. Transitioning semantic information from one layer to the next is called lowering.
To illustrate this, the Rust compiler uses four layers (I chose Rust to link to where they explain their IR layer choices):
- Abstract Syntax Tree (AST). It is represented as a tree of nodes. A strict AST faithfully captures only the parser’s understanding of the grammatical structure of a program.
- High-level Intermediate Representation (HIR). The HIR is also represented as a tree of nodes. It captures the results of semantic analysis, including syntactic sugar transformations.
- Mid-level Intermediate Representation (MIR). Rust’s MIR represents control flow as a graph. This representation simplifies lexical escape analysis, necessary to enforce move vs. drop semantics, as well as make more granular determinations of borrow lifetimes.
- Low-level Intermediate Representation (LIR). Common representations include SSA, three-address code and sea of nodes. The focus of low-level IRs (e.g., LLVM IR) is simplifying the generation of optimized code.
Cone uses only two layers: HIR (which also serves as AST) and LLVM’s low-level IR. Merging the highly-similar AST & HIR layers eliminates the performance cost of lowering all AST nodes to HIR.
Note: The Cone compiler will likely add support for MIR in the future. Doing so will improve the flexibility of lexical escape analysis and hopefully simplify LLVM-based generation of control flow.
What’s in a Node?
From now on, the term IR refers to Cone’s high-level intermediate representation, including its role as an Abstract Syntax Tree. This IR is mostly just a tree of nodes, backed up by a global name table. Nearly always, every node has only one parent (owning) node.
Each node captures some atomic piece of semantic information about the parsed program. There are dozens of flavors of nodes: one for a literal number, another for a name, another for a function call, etc. The next post will go into more detail about this.
A large part of the art in IR design lies with determining the most helpful core set of semantic elements. What makes this difficult is balancing the competing demands of the parser, semantic analysis and generation, so as to keep each of their logic straightforward and non-redundant.
Cone’s IR is lossy, in that it throws away some information visible to the lexer, such as:
- Code documentation (comments). Such information would be useful to a programmer using an editor or IDE, as provided by a language server.
- Whitespace formatting. A lossless AST is useful for a compiler that reproduces the code layout of the source program in the generated source code of the target high-level language.
Semantic Analysis
The Cone compiler currently performs only two semantic analysis passes on the IR:
- Name resolution. This binds all uses of a name to the node that declares that name. Cone’s support for forward references requires that this be a separate step.
- Type checking. This enforces static type constraints, performs needed inference, and rewrites syntactic sugar.
Among mature, well-used compilers, two is a very small number of passes. Many languages perform dozens. Some advocate the use of a nanopass compiler architecture as a helpful way to improve the maintainability and quality of a compiler’s complex semantic algorithms.
I have no doubt that Cone will add more passes in the future. A number of not-yet-implemented features, such as metaprogramming and non-lexical escape analysis, will require significant changes to how Cone handles semantic analysis. Until I deeply understand what these passes need to do and how best to sequence them, I prefer to work with a simple framework.
Node Memory Management
Cone’s compiler is written in C, primarily for performance and better control over key abstractions. As a result, the IR encoding is low-level. Each type of node is represented by a specific struct, whose fields capture all semantic information needed for that type of node. The size of a node varies depending on its type. All references to a node by its parent, or by compiler logic, are pointers.
The compiler’s allocated memory is mostly devoted to the IR data. The IR consists of many tiny pieces of data (nodes) of varying sizes. Most nodes must persist from when they are created (usually by the parser) until “consumed” by the appropriate generator.
From a performance perspective, this pattern of memory use is a good fit for arena memory management. This is what the Cone compiler uses. Essentially, it pre-allocates a very large block of memory using malloc. Then it uses a simple and fast bump pointer to deliver a small segment of memory when requested. None of this memory is freed until the compiler finishes its work. If a data segment needs to double in size, a larger area is allocated, data is copied over, and the previous data segment is abandoned.
Handling memory this way avoids the performance cost of making thousands of malloc() and free() calls. It also avoids the runtime cost of reference counting or garbage tracing, while still staying memory safe. The downside is that every resize event wastes some memory for the lifetime of the compiler. To my mind, the significant performance benefits are worth the minimal memory waste.
Cone’s IR is mutable
Semantic passes are allowed to alter the IR as they traverse it. For example:
- Inference and name resolution fills in node fields originally initialized with NULL values.
- Type checking automatically injects new nodes that explicitly (and correctly) coerce/convert a value’s type to a different type.
- De-sugaring sometimes replaces one node with another newly-created node that is (semantically) a better fit.
The benefit of IR mutation is (again) performance and memory efficiency. In-place mutation is faster than use of a persistent data store, because it significantly reduces the number of allocation and memory copy events.
I have not yet noticed any problematic side-effects from this choice, in terms of code quality or maintainability. Near-term, I have no plans to add multi-threaded support to the C compiler. In the future, I may create a multi-threaded, self-hosted compiler, but at that point I will be able to take advantage of the many ways that Cone will support multi-threaded access to mutable data structures.
That’s not all …
Other posts in this series cover:
- The INode base interface that applies to all nodes
- Named nodes, namespaces and name resolution
- Typed expression nodes and type inference
- Data Flow Analysis
This Reddit thread offers a place to discuss this post.
